
About Lorikeet Security
Lorikeet Security is a cybersecurity firm based in Orlando, Florida specializing in penetration testing, red team operations, compliance consulting, and live cyber training events. Founded by Ryan Wilke in 2021, the company has grown from a single CTF training platform (originally launched as Parrot CTFs) into a full-spectrum offensive security and training operation, with 50+ events hosted and over 15,000 participants trained to date.
Lorikeet Security training events deliver live CTF competitions and hands-on labs across web exploitation, reverse engineering, cryptography, active directory, and forensics. Events range from 200-person corporate workshops to 1,000-person conference competitions, each running against dedicated isolated infrastructure with per-team VPN access and no shared resources. With a 99.9% uptime record across 50+ events, infrastructure reliability is a core part of Lorikeet's offering, and something their clients explicitly rely on.
The Challenge
Lorikeet's training event infrastructure runs on a cluster of dedicated bare-metal servers handling three distinct workloads: the challenge platform (scenarios, labs, scoring engine), a CTF server running intentionally vulnerable environments for participants, and a media relay node for the instructor's live session. During an event, all three nodes are under simultaneous load from participants' VPN connections; there is no graceful degradation. If any node saturates, the session stops.
Prior to deploying Flowtriq, Lorikeet had no automated DDoS detection in place. When connectivity degraded during an event, the response was entirely manual: identify the issue, determine the right rule, coordinate with the upstream provider. By the time that cycle completed, the damage was already done.
"We'd had events where connectivity would get weird and we'd spend ten minutes just figuring out if it was our stack or the network. With two hundred-plus people connected and a training schedule running, that ten minutes is real damage. You can't get that time back once a session goes sideways."
Ryan Wilke, CEO & Founder, Lorikeet Security
How the alternatives compare
| Capability | FastNetMon CE [1] | Wanguard | Arbor / NETSCOUT | Flowtriq |
|---|---|---|---|---|
| Detection granularity | Flow-based, threshold (30–60s) [1] | Flow-based (30–60s) | Flow-based (30s+) | Per-second (<1s) |
| BGP FlowSpec | Advanced only — not in CE [1] | Add-on module | Yes (enterprise tier) | Included, all plans |
| Cloud scrubbing integration | No [1] | Manual config | Vendor-specific | Built-in, one-click |
| Auto upstream mitigation | BGP blackhole (RTBH) via ExaBGP [1] | Partial | Yes | Yes, or one-click |
| Multi-vector co-detection | No [1] | Sequential | Yes | Yes, single cycle |
| Upstream coordination | Blackhole only — no scrubbing automation [1] | Partial automation | Often manual | Fully automated |
| Time to deploy | Hours–days (dedicated server + flow infra required) [2] | Days (on-prem appliance) | Days–weeks | ~2 min/node |
Publicly announced events are a known DDoS targeting surface.
Lorikeet's training events are listed on a public schedule with exact dates, times, and registration pages. That is all an attacker needs to time a volumetric hit for maximum impact: peak participant load, mid-session, when any outage has the most visible and irreversible cost. Live events, public product launches, conference streams, and scheduled maintenance windows all share this pattern. The attack window is predictable, and the cost of downtime is highest precisely when the event is running. Any operator hosting publicly announced events on dedicated infrastructure should treat the public schedule itself as part of the threat model.
Flowtriq was deployed across all three Lorikeet nodes in approximately 10 minutes during a pre-event infrastructure check the week before March 27. The ftagent installed on each node, spent roughly five minutes learning each node's baseline traffic profile, and had both the BGP FlowSpec adapter and cloud scrubbing integrations confirmed active before the event went live.
The Event: March 27, 2026
The event in question was a March 27, 2026 public live cybersecurity training event, a full-day hands-on session running from 09:00–17:00 EST with approximately 240 registered participants. The curriculum covered active network threat identification, live packet analysis, and escalating incident response scenarios, all running against Lorikeet's dedicated infrastructure. By 09:45, all three nodes were under typical event load: steady streams from participants' VPN connections, scoring engine calls, and the instructor livestream.
At 09:52:14, the attack began.
What Happened: Minute by Minute
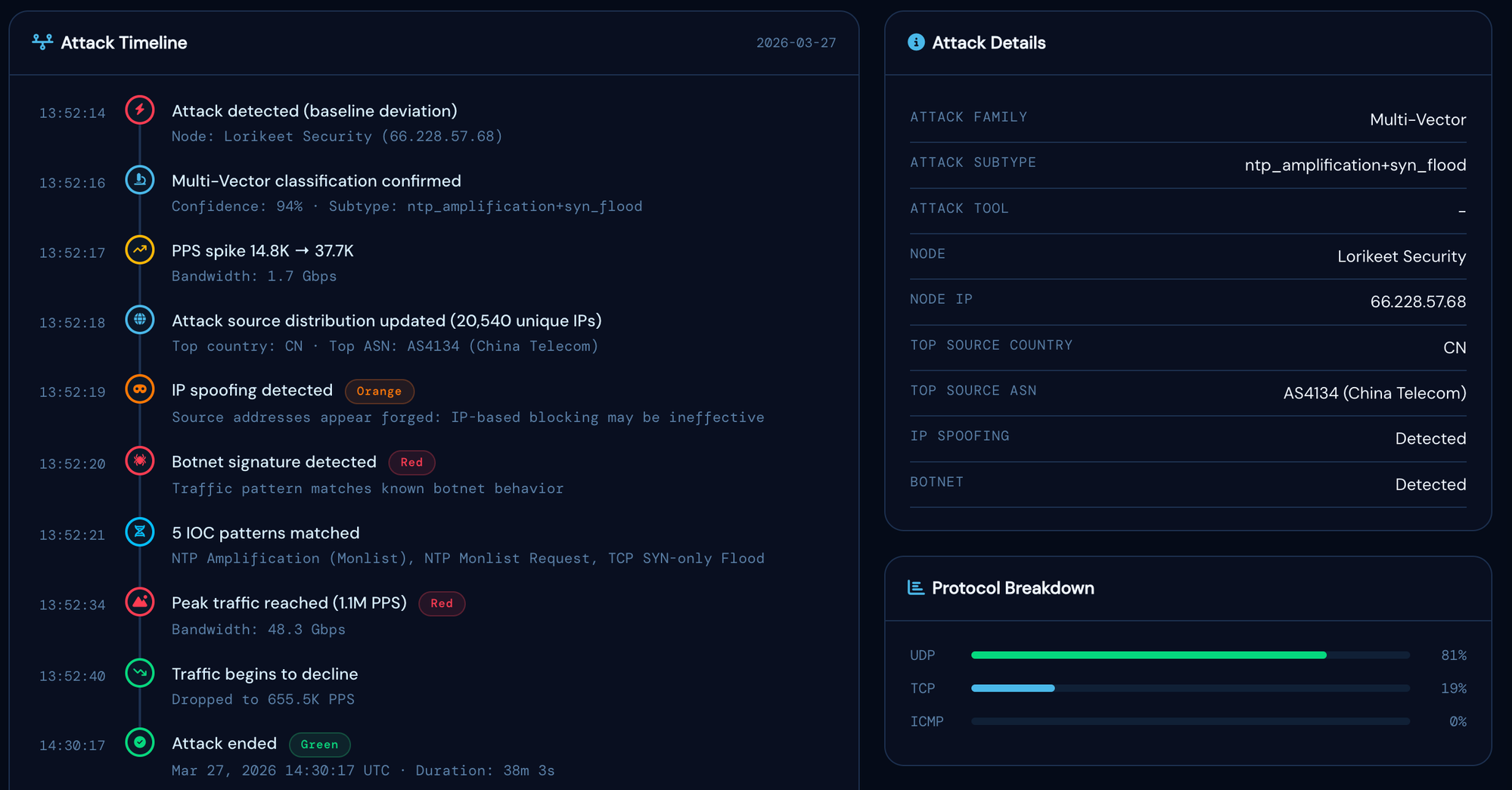
From the perspective of the 240 participants in the event, nothing happened. No latency spike was visible in the training platform. The instructor's stream did not buffer. The CTF scoring engine did not hiccup. The only indication that anything had occurred was the Slack alert thread, which the infrastructure engineer had been monitoring silently in the background.
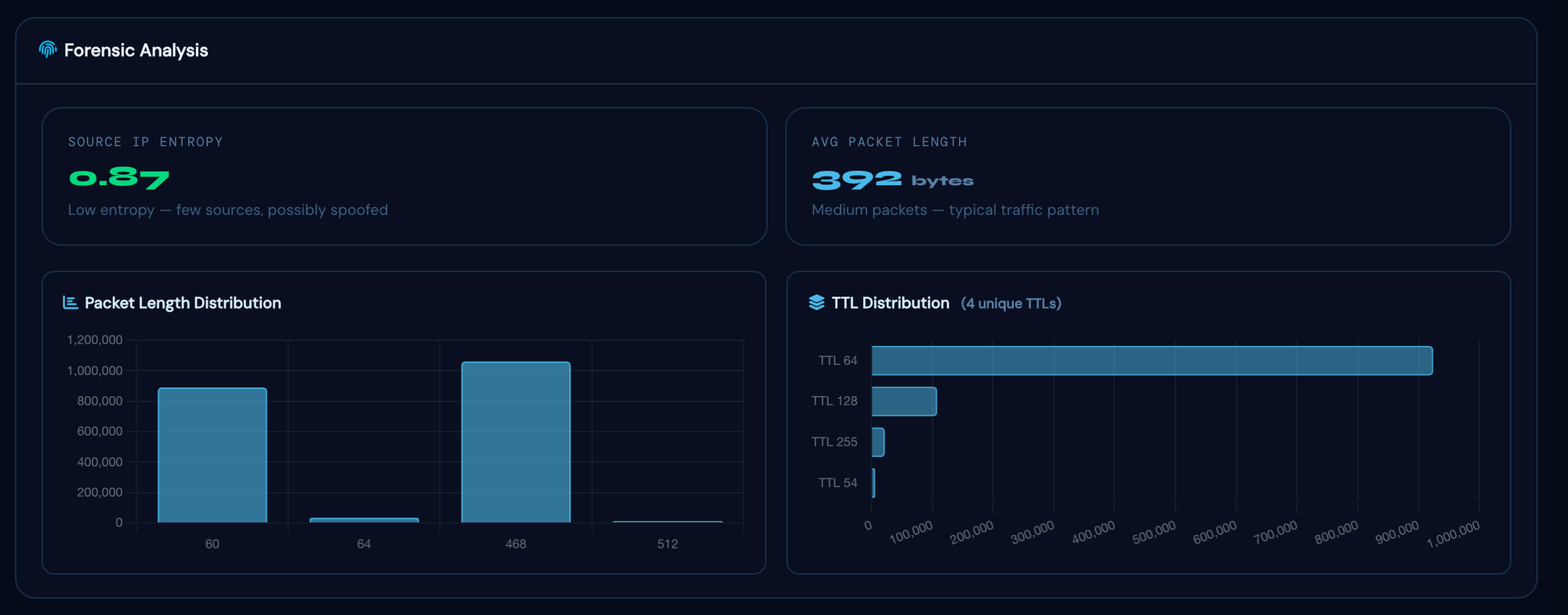
Attack Technical Breakdown
The post-incident PCAP analysis confirmed a coordinated multi-vector attack with two distinct components, likely launched from separate hired botnet infrastructure.
Vector 1: NTP Amplification
Vector 2: SYN Flood
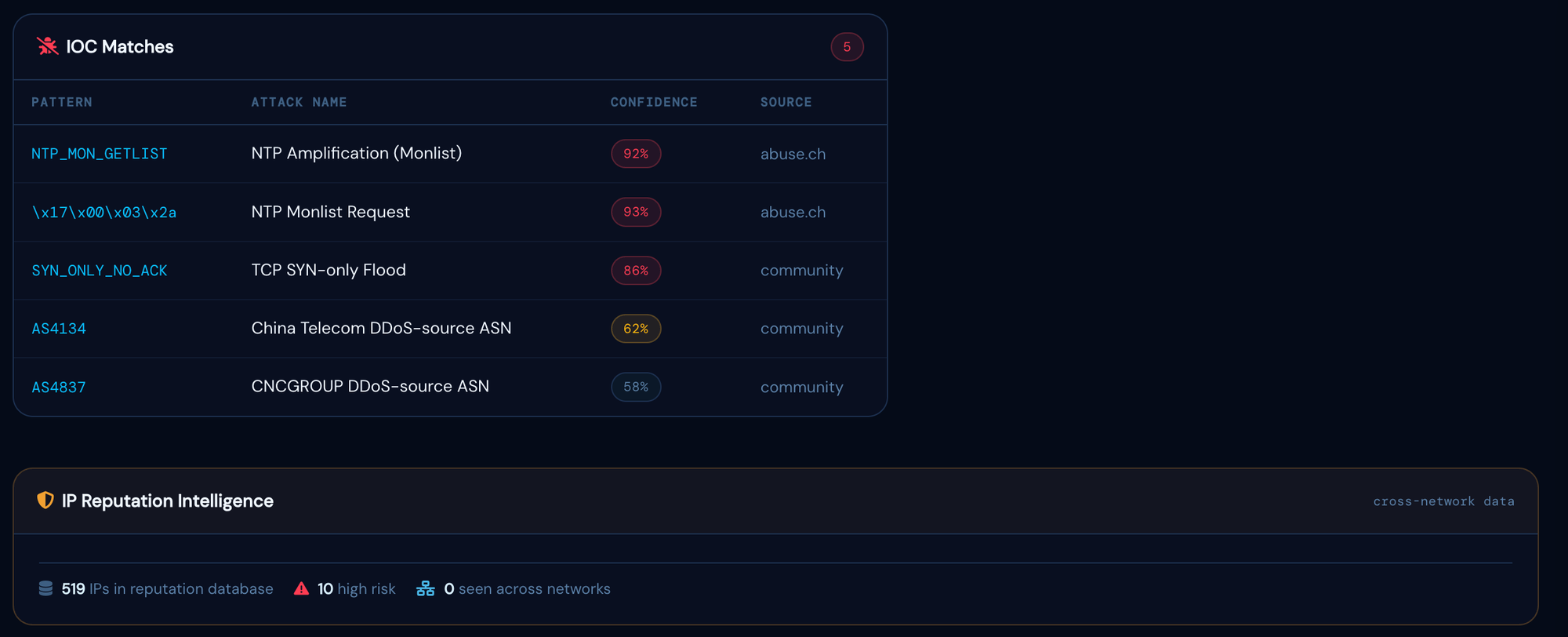
Why multi-vector attacks are harder to stop without tooling: The NTP amplification and SYN flood components required two distinct mitigation responses: a source-port-based FlowSpec rule for the amplification traffic and a source-prefix rule for the spoofed SYN traffic. Without per-second classification identifying both vectors simultaneously, a manual response would likely have addressed one while the other continued to saturate the uplink.
Why the Attack Did Not Take Down the Event
There are three reasons the infrastructure stayed up, and they are worth separating clearly.
Speed of detection. The 0.9-second detection window means Flowtriq identified the attack before it reached peak volume. NTP amplification attacks typically ramp to maximum throughput over 5–15 seconds as reflected packets begin returning from the amplifiers. Catching the attack in the ramp phase, before the uplink saturated, gave the mitigation rules time to take effect before bandwidth was exhausted.
On-node mitigation as a first line. The automatic iptables rules pushed by Flowtriq at T+8s protected application processes even before the upstream BGP rules were in place. The nodes continued accepting legitimate traffic from participants' VPN addresses (those IPs were not in the attack source ranges and passed through cleanly) while all other inbound traffic matching the attack signature was dropped at the kernel level.
Unified upstream mitigation, not just BGP. On-node iptables rules protect the server's CPU and application layer, but they do not recover saturated uplink bandwidth; traffic still has to traverse the ISP's network before being dropped. Flowtriq moved the drop point upstream in two ways simultaneously: BGP FlowSpec rules pushed to the transit provider's edge, and a cloud scrubbing integration routing traffic through an additional upstream layer. The combination meant attack traffic was being discarded at multiple points before it could reach Lorikeet's uplink at all.
Industry context: why manual response is not fast enough
Security operations research puts manual DDoS response workflows at a minimum of 15–30 minutes under best-case conditions: alert triage, vector classification, strategy selection, and upstream provider coordination. NETSCOUT's 2024 Threat Intelligence Report found that 70% of DDoS attacks last fewer than 15 minutes. This creates a structural gap: most attacks resolve on their own or cause their maximum damage before a manual response process can push an upstream rule. Flowtriq completed the same detection-to-upstream cycle in 11 seconds.
Where the attack traffic was stopped
"We had 240 people in a live cybersecurity event and took close to 50 gigabits of attack traffic mid-session. The Flowtriq alert landed in our Slack before I'd even registered anything was wrong on the dashboard. By the time I pulled up the incident view, the on-node rules had already fired, BGP FlowSpec was pushed to our upstream, and cloud scrubbing was routing traffic through an additional layer. Full mitigation stack active in under 15 seconds from detection. Not one participant noticed anything happened."
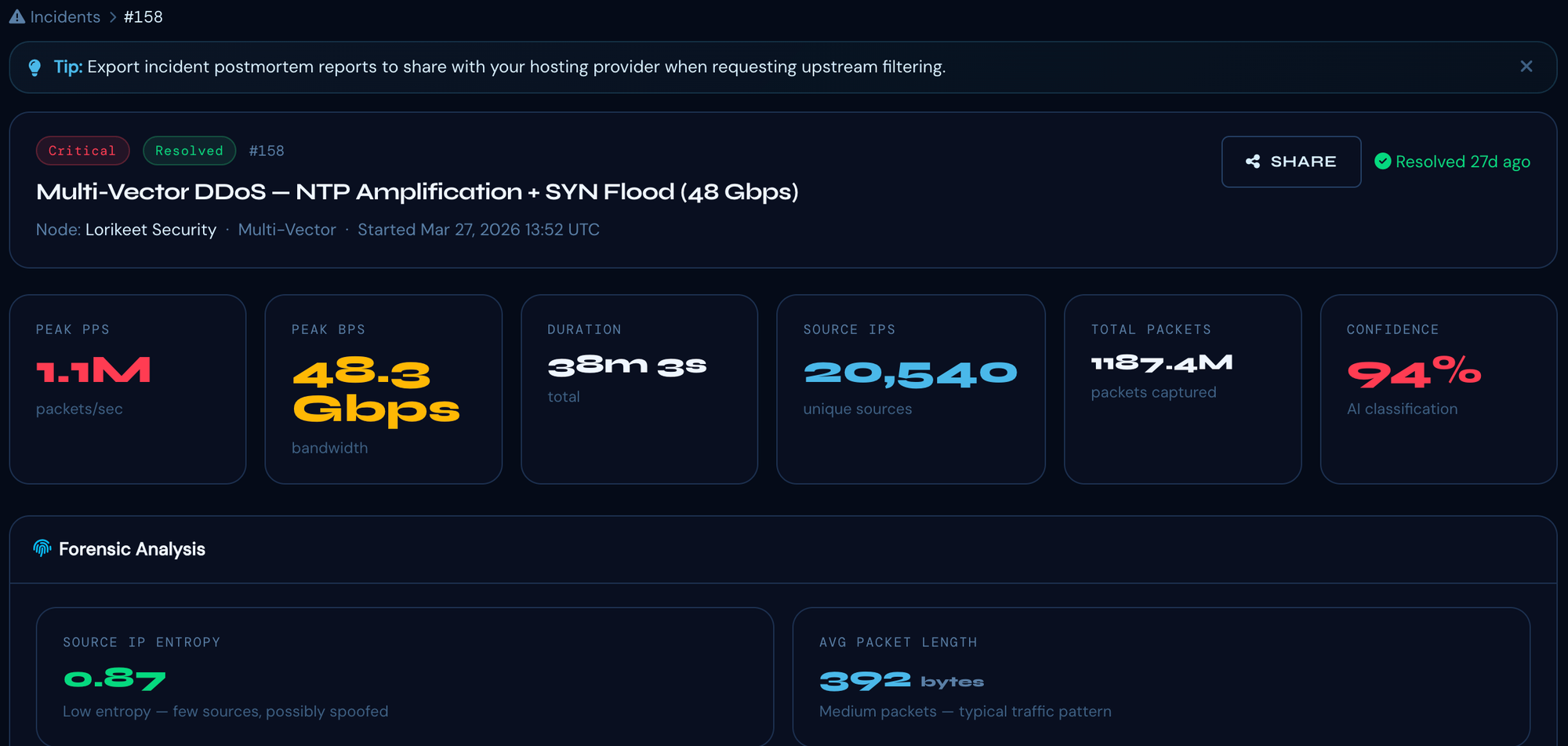
Outcomes
Participants stayed connected throughout the full event
From first packet detected to upstream BGP FlowSpec rule active
All three nodes remained fully operational throughout the 38-minute attack
Automated capture available for post-incident forensics and upstream ISP coordination
NTP amplification and SYN flood handled with independent targeted rules
48 Gbps scrubbed upstream; bandwidth never exhausted at Lorikeet's edge
Business impact: Lorikeet's contract for the March 27 event with [enterprise client, name redacted per NDA] carried a formal uptime SLA for the contracted training window, with breach provisions triggered by any outage exceeding 15 consecutive minutes and a mandatory reschedule obligation at Lorikeet's cost. A manual response to a 48 Gbps multi-vector attack would typically require 30 to 60 minutes under best-case conditions. The automated mitigation cycle completed in under 20 seconds. No SLA clause was triggered. No reschedule was required.
What Lorikeet Does Now
Following the March 27 event, Lorikeet Security standardised Flowtriq across all event infrastructure as a required component of pre-flight. Every session now includes a dedicated infrastructure check: FlowSpec adapter connected, cloud scrubbing integrations verified, alert channels confirmed and routed to whoever is on duty that day. Flowtriq runs year-round on all three nodes. Since March, it has automatically blocked two additional lower-volume probes against the CTF server without any manual intervention required.
"Every event now runs a Flowtriq pre-flight before we let participants in. FlowSpec connected, cloud scrubbing verified, alerts confirmed. It's become as standard as checking that the VPNs are up. Since March we've had two more automated blocks on the CTF server. I didn't even know about them until I checked the incident log."
Ryan Wilke, CEO & Founder, Lorikeet Security
Flowtriq Features Used
- Per-second anomaly detection: ftagent on each node, monitoring PPS/BPS deviations against dynamic baselines
- Multi-vector co-detection: both attack vectors flagged in a single incident within the same detection cycle
- Slack alerting: real-time incident notification with classification, affected nodes, and live dashboard link
- Auto-mitigation rules: pre-configured iptables rules pushed automatically on matching attack signatures
- BGP FlowSpec adapter: upstream rules pushed to transit provider edge routers via Flowtriq's one-click interface
- Cloud scrubbing integration: cloud-layer scrubbing activated alongside BGP FlowSpec for a unified upstream mitigation approach
- PCAP capture: automatic packet capture triggered at incident detection, stored for forensics and download
- Live incident view: real-time traffic graphs, source IP map, and mitigation controls in the dashboard
Protect your next live event, or any infrastructure that can't afford downtime
Flowtriq takes under two minutes to deploy. Per-second detection, automatic mitigation, BGP FlowSpec upstream rules, and instant alerts. Starting at $9.99/node/month.
Start Free Trial →No credit card required · 14-day free trial